Données fixes et données variables
Une table PostgreSQL traditionnelle est composée d'un ensemble de colonnes qui structurent les données que la table pourra contenir. Ces données sont considérées comme des données fixes car chaque tuple dépendront du même contexte et des mêmes règles.
L'extension pgSQLPlus introduit la notion de données variables : il devient alors possible, pour chaque tuple d'une table, de lui associer des données qui dépendent d'une autre table. On dit que la table possède alors une variance.
Cette variance est équivalant à une table à part entière qui supporte les mêmes fonctionnalités qu'une table classique : ajout de colonne, contraintes, index etc...
Une table peut posséder plusieurs variances et la création de variances pouvant se faire de manière récursive,une variance peut elle-même posséder une ou plusieurs variances.
La récupération des données d'une table possèdant une variance se fait dans les mêmes conditions qu'habituellement mais des paramètres de variances devront être également fournis.
Caractéristiques
Une variance se caractérise par deux éléments : une colonne source et une colonne cible.
La colonne source définit la colonne que l'extension devra utiliser afin d'associer les données variables et les données fixes. Cette colonne doit rendre chaque tuple unique dans sa table. En ce sens, une clef primaire, un index ou une contrainte d'unicité devra lui être associé.
La colonne source est obligatoirement une colonne de la table à laquelle la variance appartient. Dans le cas d'une variance de variance, la colonne source doit appartenir à la variance parente.
La colonne cible définit la colonne sur laquelle les données variables vont devoir être itérées. Cette colonne doit rendre chaque tuple unique dans sa table. En ce sens, une clef primaire, un index ou une contrainte d'unicité devra lui être associé.
Exemple
Imaginons une base de données ayant pour but de représenter un catalogue de produits avec support multilingue et dont le prix des produits varie selon les jours de la semaine.
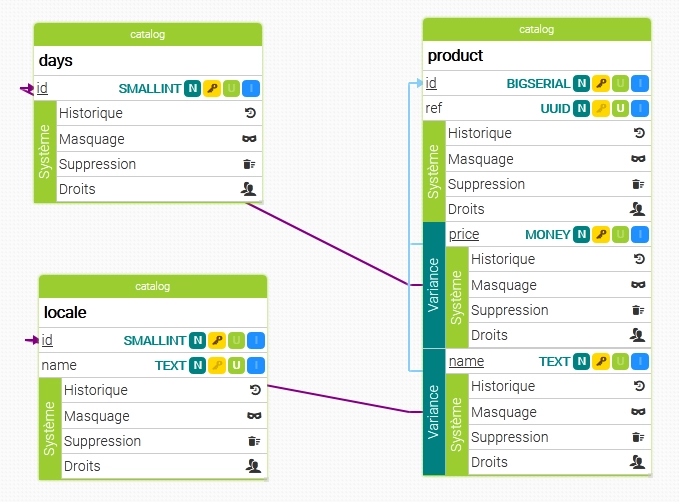
En utilisant le principe des données variables, une telle base de données ressemblerait au schéma ci-dessous :

Ici, la table product est destinée à contenir l'ensemble des produits du catalogue (schéma catalog). Elle possède un identifiant unique à incrémentation automatique, la colonne id, ainsi qu'une colonne ref destinée à stocker la référence de chaque produit.
Elle possède également deux variances : une destinée à rendre variant le prix du produit et une autre destinée à rendre variant le nom du produit. Les deux variances ont pour colonne source la colonne id de la table product mais la première variance utilise comme colonne cible idde la table days et la seconde variance utilise la colonne id de la table locale comme colonne cible.
Ainsi, chaque produit aura un identifiant et une référence mais également un nom, dépendant de la langue, ainsi qu'un prix, dépendant du jour de la semaine.
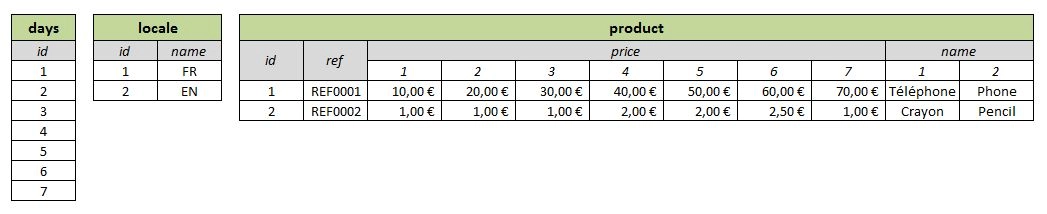
La base de données pourra, par exemple, contenir des données telles que ci-dessous :

Deux langues différentes sont définies : le Français et l'Anglais, ainsi que les 7 jours de la semaine. Les deux produits enregistrés ont chacun 7 prix différents et un nom, variable selon la langue.
Lors de la sélection des produits, en fonction du jour de la semaine et de la locale précisée en paramètre de la requête, les produits auront toujours les mêmes identifiants et références mais leur prix et leur nom changeront.
Précédent
Droits sur les donnéesSuivant
Objet de sélection